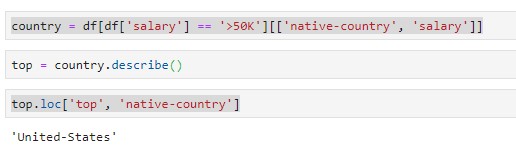
# Defining the new columns in a new grouped table
aggregation = {
'>50K': ('salary', lambda x: (x == ">50K").sum()),
'<=50K': ('salary', lambda x: (x == "<=50K").sum()),
}
# Creating a new table that has native-country as the index and columns that have the counts of >50K and <=50K
df2 = df.groupby('native-country').agg(**aggregation)
# Function that gets the total per country
def getTotal(row):
return row['>50K'] + row['<=50K']
# Add a column that calculate the % of those that earn >50K
df2['>50K%'] = df2.apply(lambda row: (row['>50K'] / getTotal(row) *100).round(1), axis=1)
# Sorting the values by >50K% - largest number at the top
df2 = df2.sort_values(">50K%",ascending=False)
# Get the name of the country and put into Title Case
highest_earning_country = df2.iloc[0].name.title()
# Get the percentage
highest_earning_country_percentage = df2.iloc[0][">50K%"]