I got lucky and had a technical interview with recruiting company that was recruiting for a local company hiring for PHP developer which I failed, I was lucky to make it to a technical interview normally I dont get them.
The problem sets in this [backend interview] (ive included my solutions)(https://github.com/KravMaguy/Technical-interview/tree/master/Backend%20interview) were all easy except the last one, which I could not do:
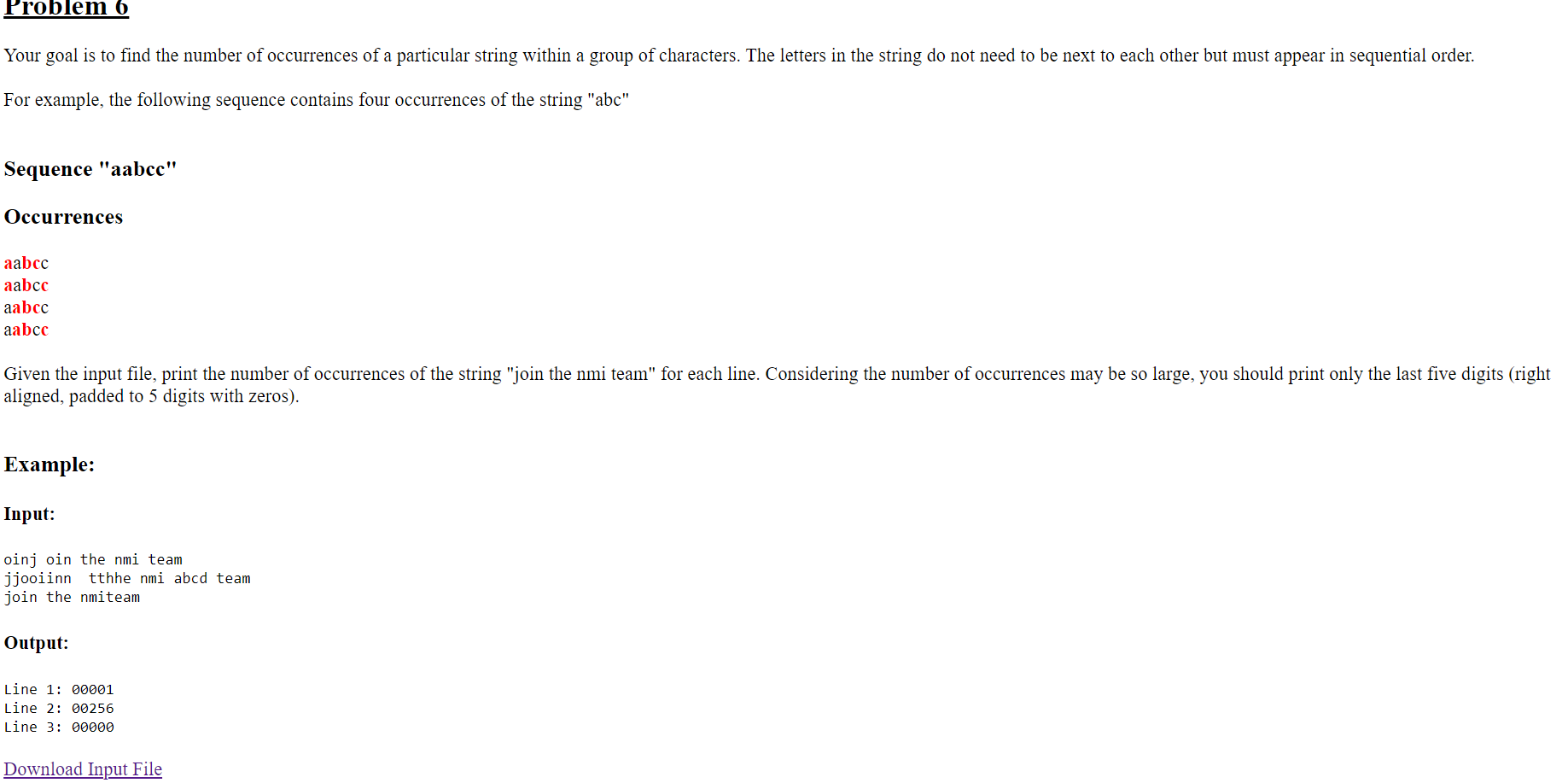
for the example ignore the part about the padding with the digits.. and the lines of the file (they are just individual haystacks)
what Ive done:
to get the number or occurances create hashmap of letter occurances and their indexes and multiply length of each letter array (wont work because the letters of the needle in the haystack need to be in order)
e.g. for a needle “ABCDE” A must come before B which much come before C which must come before D which must come before E etc..
I was told to use a queue, I did not invent his solution:
while (queue.length > 0) {
const [val, idx] = queue.shift();
if (idx === str.length - 1) {
count++;
} else {
const arr = hashMap[str[idx + 1]];
for (let i = 0; i < arr.length; i++) {
if (val < arr[i]) {
queue.push([arr[i], idx + 1]);
}
}
}
}
but anyways it didnt work with large inputs the queue is becoming massive for every single one removed from it. In some of the test cases in the input file there is an astronomical number of possibilites.
Here is what I think to do, I need your help to implement it:
consider inputs
hayStack: “xBxxAxxBxCxBxAxBxC”
needle: “ABC”
I will look for the first occurance of A followed by whatever occurance of B that comes after the A followed by whatever occurance of C that comes after the B. now that ive found the first occurance I will iterate through all the C’s that come after that C until no more C’s.
I will then work backwards so I will proceed to the next B than look for all the C’s until there are no more, then go to the next B repeat look for all the C’s until there are no more, advance to the next B and look for all the C’s until no more C’s, repeat this process until there are no more B’s
Now im back to the first A, so I will advance to the second A and do the same process I described above until no more A’s
for the sample inputs above we have keys for each letter and values being arrays of indeces e.g.:
[ 'A', [ 4, 13 ] ]
[ 'B', [ 1, 7, 11, 15 ] ]
[ 'C', [ 9, 17 ] ]
what im seeing is it needs to pop twice each time it gets to the end of a given lettersArray.
can you please describe this process, goes without saying it needs to work with any length of inputs.:
//[A, B, C]
[4 ,7, 9 ] +1
[4, 7, ] pop(9)
[4, 7, 17] +1 push(17)
[4, , ] pop(17) pop(7)
[4, 11, ] push(11)
[4, 11, 17] +1 //can not add 9 it is less than 11, push(17)
[4, , ] pop(17) pop(11)
[4, 15, ] push(15)
[4, 15, 17] +1 //can not add 9, push(17)
[ , , ] pop(17) pop(15) pop(4)
[13, 15, 17 ] +1
//5 possibilities
//5 possibilities
I wrote some code but its not correct.
function findNumOccurances(sequence, str) {
const stack = [];
const hashMap = [...sequence].reduce((acc, letter, idx) => {
acc.hasOwnProperty(letter) ? acc[letter].push(idx) : (acc[letter] = [idx]);
return acc;
}, {});
for (let i = 0; i < str.length; i++) {
const letter = str[i];
const arr = hashMap[letter];
for (let j = 0; j < arr.length; j++) {
const val = arr[j];
if (stack.length < 1) {
stack.push([val, j, letter]);
break;
} else {
if (val > stack[stack.length - 1][0]) {
stack.push([val, j, letter]);
break;
}
}
}
}
const stackCombos = [];
while (stack.length > 0) {
if (stack.length === str.length) {
stackCombos.push([...stack]);
}
const [val, index, key] = stack.pop();
const lettersArray = hashMap[key];
if(index<lettersArray.length-1){
stack.push([lettersArray[index + 1], index + 1, key]);
} else {
const popped=stack.pop()
if(!popped){continue}
const [poppedVal, poppedIdx, poppedKey]= popped
if(poppedIdx<hashMap[poppedKey].length-1){
const pushedKey=[hashMap[poppedKey][poppedIdx+1],poppedIdx+1, poppedKey]
stack.push(pushedKey)
while(stack.length<str.length){
for(let j=0;j<lettersArray.length;j++){
if(lettersArray[j]>pushedKey[0]){
stack.push([lettersArray[j], j, key])
break
}
}
break
}
}
}
console.log({stack})
}
console.log('-------------------------------------')
console.log('possibilities \n',stackCombos)
}
const testCases = ["xBxxAxxBxCxBxAxBxC"];
// ["012345678901234567890"]
const str = "ABC";
for (let [index, value] of testCases.entries()) {
findNumOccurances(value, str);
}
edit: assume in the stack initial setup process ill add a check to make sure its equal to the needle length and return zero occurances immediately if not
edit #2: somethings about this algorithm I realized:
Each character in the needle is a loop, the last character in the needle (the top of the stack), every time its set or changes we can add one to total occurances.
each character loop advances once in its letters array for the completion of the entire letters array for the character that follows it and so on for each character in the needle.

