Tell us what’s happening: Why is this regex not able to select a string with whitespaces at beginning and the end and then replace it with the middle string only(without the extreme spaces)?
Your code so far
let hello = " Hello, World! ";//string with spaces at start and end
let wsRegex = /^\s*(.+)\s*$/; // regex to select a string (.+) with spaces at beginning and end
let result = hello.replace(wsRegex, "$1"); // replacing the selected text with the string enclosed between the spaces
console.log(result); //it does log "Hello, World!" as expected but test-run gives the error <error>result should equal to "Hello, World!"</error>
Your browser information:
User Agent is: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75.
PS: The regex to select only the spaces at start and end , /^\s+|\s+$/g works perfectly well and they can be replaced with “” to remove them. But, the above question still stands^^^
@ILM I think it ought to be the default greedy matching since we’re supposed to match the entire string wrapped by whitespaces. Using lazy matching would cause to the search to terminate at the middle space between “Hello” and “World!”, right? But, even the greedy matching doesn’t seem to work here. I just can’t figure out why though?
\s*(.+)\s* is “0 or more spaces, followed by one or more of any character, followed by 0 or more spaces”. You match a few spaces at the start, then the (.+) matches the rest.
Edit: look
" Hello, World! "
^|_||_____________|$
Start of string
3 spaces (“zero or more spaces”)
Any characters (“one or more of any character”)
No spaces (so, nothing to match, “zero or more spaces”)
End of string
let hello = " Hello, World! ";
let wsRegex = /^(\s*)(.+[^\s*$])(\s*)$/;
let result = hello.replace(wsRegex, "$2");
console.log(result);
This regex /^(\s*)(.+[^\s*$])(\s*)$/ works for this problem.
These are the matching groups in our expression:
1
^(\s)*
match any number of white spaces at the start
2
(.+[^\s*$]$
match any number of characters excluding the spaces at the end
3
(\s*)$
match all the trailing spaces
So, clearly we want to retain only the part matching the second matching group. Thus, we replace the entire string with the text selected by the second group as shown
let result = hello.replace(wsRegex, "$2");
The problem with the initial regex /^\s*(.+)\s*/ was that (.+) part was including the trailing spaces too because the wildcard character includes whitespaces too.
Please let me know if I my line of thinking is correct or not.
Yes, thank you very much for the explanation. I didn’t realize that the wildcard character would include whitespaces too … I replaced the capturing group (.+) by (.+[^\s*$]) to exclude the trailing spaces from being captured by it. Now, it works well!
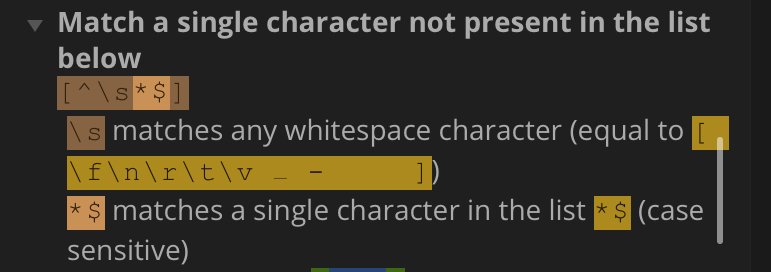
this is not doing what you want, you are saying to match something that is not a space, an asterisk or dollar sign - if you have doubts, a tool like regex101.com is essential
Yes, this matching group works pretty nicely. Thanks for pointing out the redundancy of * and $ in (.+[^\s*$]).
About the lazy mode matching that you suggested, it works but I can’t comprehend how it works…
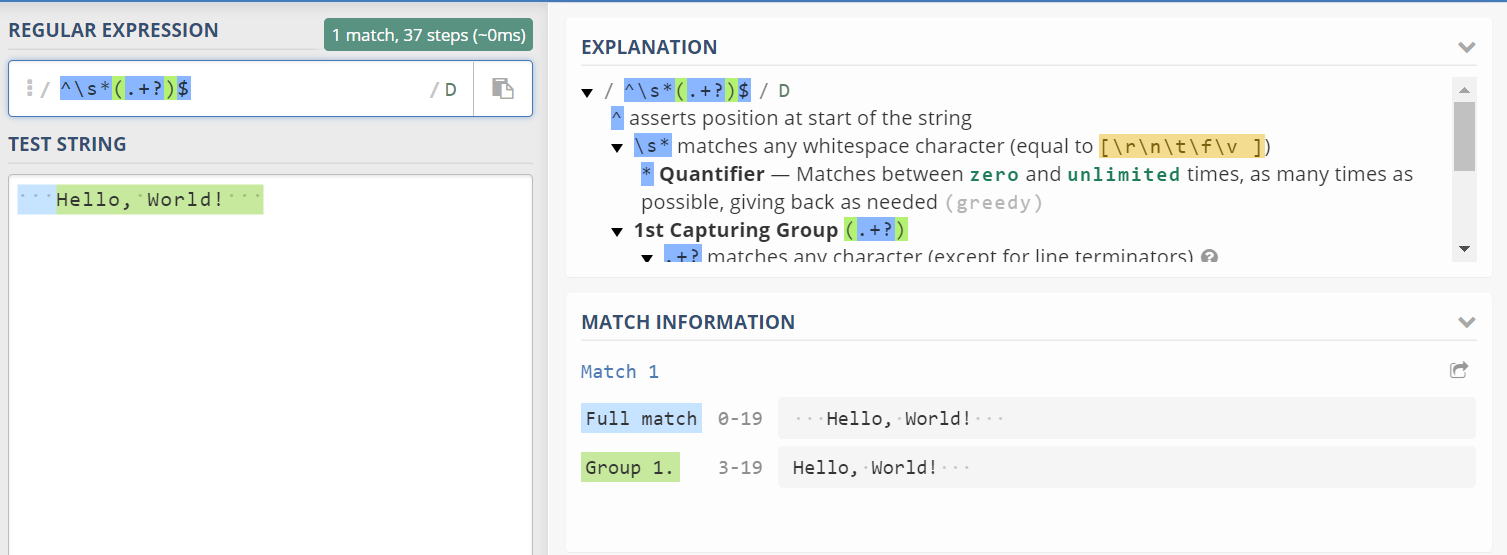
/^\s*(.+?)\s*$/
The group (.+?) would capture all characters except for line terminators. So wouldn’t it include the trailing spaces at the end of the string? Or would it capture the MINIMUM possible characters that it matches with? Would it be right to say that, if \s* had not been at the end, it would match with the entire string along with the ending whitespaces? So technically, in the lazy mode, the capturing group would bear the least possible burden, i.e; capture the smallest string possible?(hence, the name “lazy”)
I meant the entire regular expression(including ^ and $) without the ending \s*. The presence of \s* at the end causes the (.+?) to match the “Hello, World!” part only???
I’m really sorry but this is my first time with regular expressions. Thank you very much for all the help!