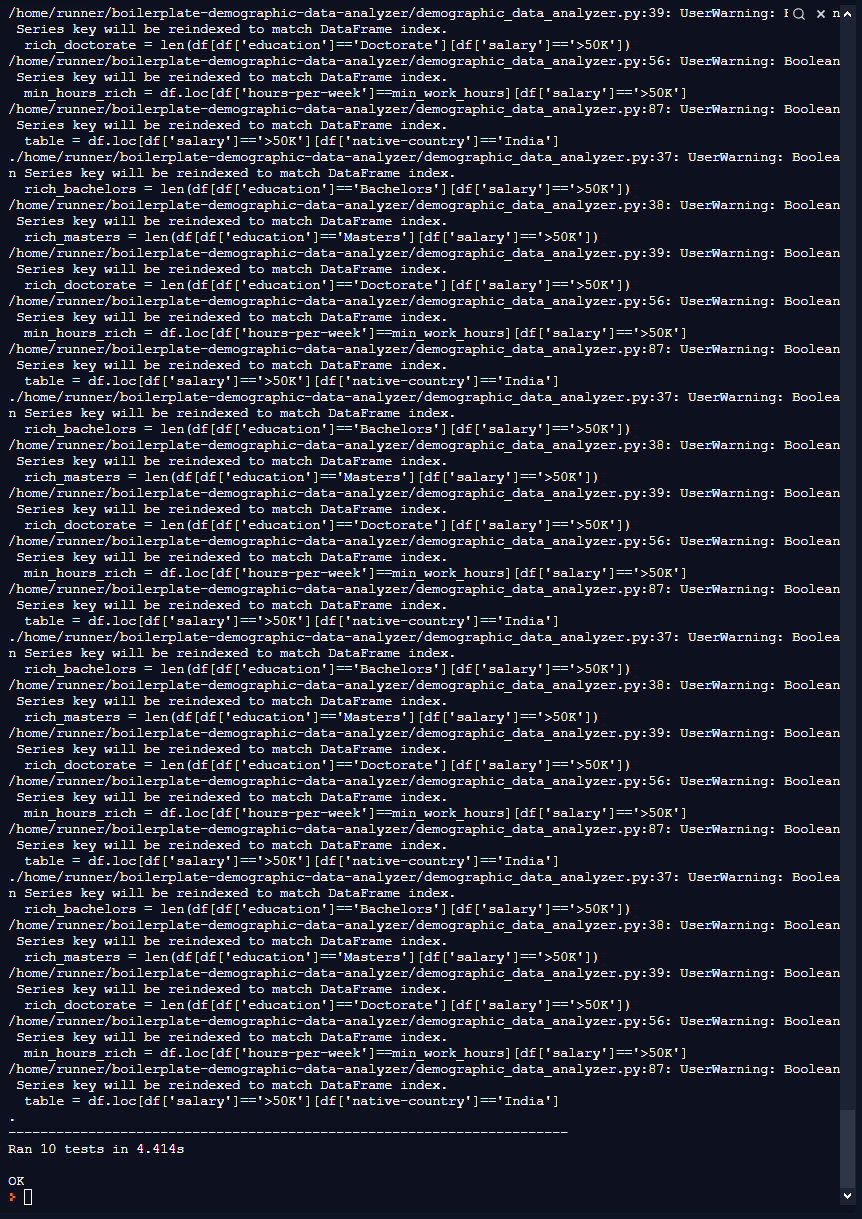
Hi All,
I have completed the Demographic Data Analyzer project. The tests run fine however there are many warnings being generated and I do not understand what the warnings are trying to say.
Would appreciate if someone could explain what the warnings are about and if my code in pandas have any syntax issue?
Thanks in advance.
Google’s first result on the error. I bet it’s the implicit and in your dataframe selections.
This is much easier if you post the error messages as text (extra points for a code block) instead of images and you’ll get even better advice if you post links to your project’s code at repl.it or the like.
Hi Jeremy,
Thanks for your reply but I still don’t understand after reading the link you shared, I also googled for it earlier but did not understand the explanation.
One of the warnings with a snippet of my code is as follow;
Read data from file
df = pd.read_csv('adult.data.csv')
percentage with salary >50K
rich_bachelors = len(df[df['education']=='Bachelors'][df['salary']=='>50K'])
rich_masters = len(df[df['education']=='Masters'][df['salary']=='>50K'])
rich_doctorate = len(df[df['education']=='Doctorate'][df['salary']=='>50K'])
total_highED_rich = rich_bachelors + rich_masters + rich_doctorate
higher_education_rich = (total_highED_rich / higher_education * 100).round(decimals=1)
I did not get any error messages from the test script only those warnings above, and there are many of them yet it prints and returns just fine.
They’re just warnings, yes. Your code looks almost like the original question’s code in the SO post. I think the first suggestion or something similar from the accepted answer is the fix to get rid of the warnings. It’s warning about stuff like this
where you have multiple selection criteria and no logical operator (implicit and, I would guess). As suggested in the SO answer, try using & between the selection criteria. But this is just a guess as we’d have to see the project to definitively fix it.
Hi Jeremy,
I tried the following, none of which work, they threw error 137 (run out of memory)
rich_doctorate = len(df[df['education']=='Doctorate'] & [df['salary']=='>50K'])
rich_doctorate = len(df[df['education']=='Doctorate'] & df['salary']=='>50K')
rich_doctorate = df[df['education']=='Doctorate'] & [df['salary']=='>50K']
Thanks for your help. I might be facing a different issue than the question in the other post though the code does look similar.
Hi Jeremy,
I found the solution. I changed my code to the following:
bachelors = df.loc[df[‘education’]==‘Bachelors’]
rich_bachelors = bachelors.loc[df[‘salary’]==‘>50K’]
masters = df.loc[df[‘education’]==‘Masters’]
rich_masters = masters.loc[df[‘salary’]==‘>50K’]
doctorate = df.loc[df[‘education’]==‘Doctorate’]
rich_doctorate = doctorate.loc[df[‘salary’]==‘>50K’]
total_highED_rich = len(rich_bachelors) + len(rich_masters) + len(rich_doctorate)
It seems like in my previous code, I was calling df on two separate nested data frames which I thought I was calling the same data frame that caused the warning. But if I break up the df and assign it as another dataframe and apply the next filter to it the warning does not show up.
Edit:
Alternatively I also found out that to apply the filters all at once, I would need to change the brackets from square to round. The following would work as well.
rich_bachelors = df.loc[(df[‘education’]==‘Bachelors’) & (df[‘salary’]==‘>50K’)]
Glad you worked it out. Keep this in mind when you do the medical data heatmap as you’ll need a similar bit of code when cleaning the data.