Article on Headers and Cookies for Web Scraping was originally published on Scraper API.
As technology advances, web servers are getting better at differentiating user traffic from web scrapers, making it harder for all of us to access the data we need.
Although there are many methods we can use to circumvent many security measures, there’s one, in particular, that doesn’t get enough attention: custom HTTP headers.
In today’s article, we’ll dive deeper into what HTTP headers are, why are they important for web scraping, and how we can grab and use them in our code.
What are HTTP Headers?
According to MDN “ An HTTP header is a field of an HTTP request or response that passes additional context and metadata about the request or response”, and consists of a case-sensitive name (like age, cache-control, Date, cookie, etc) followed by a colon (![]() and then its value.
and then its value.
In simpler terms, the user/client sends a request containing request headers providing more details to the server. Then, the server responds with the data requested in the structure that fits the specifications contained in the request header.
For clarity, here’s the request header our browser is sending Prerender at the time writing this article:
1 authority: **in**.hotjar.com
2 :method: POST
3 :path: **/**api**/**v2**/**client**/**sites**/**2829708**/**visit**-**data?sv**=**7
4 :scheme: https
5 accept: ***/***
6 accept**-**encoding: gzip, deflate, br
7 accept**-**language: en**-**US,en;q**=**0.9,it;q**=**0.8,es;q**=**0.7
8 content**-**length: 112
9 content**-**type: text**/**plain; charset**=**UTF**-**8
10 origin: [https:**//**prerender.io](https://prerender.io/)
11 referer: [https:**//**prerender.io**/**](https://prerender.io/)
12 sec**-**ch**-**ua: " Not A;Brand";v**=**"99", "Chromium";v**=**"101", "Microsoft Edge";v**=**"101"
13 sec**-**ch**-**ua**-**mobile: ?0
14 sec**-**ch**-**ua**-**platform: "macOS"
15 sec**-**fetch**-**dest: empty
16 sec**-**fetch**-**mode: cors
17 sec**-**fetch**-**site: cross**-**site
18 user**-**agent: Mozilla**/**5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit**/**537.36 (KHTML, like Gecko) Chrome**/**101.0.4951.64 Safari**/**537.36 Edg**/**101.0.1210.47
What are Web Cookies?
Web cookies, also known as HTTP cookies or browser cookies, are a piece of data sent by a server (HTTP response header) to a user’s browser for later identification. In a later request (HTTP header request), the browser will send the cookie back to the server, making it possible for the server to recognize the browser.
Websites and web applications use cookies for session management (like keeping you logged in), personalization (to keep settings and preferences), tracking, and in some cases security.
Let’s see what a cookie would look like in LinkedIn’s request header:

Why are Headers Important for Web Scraping?
A lot of website owners know their data will be scraped one way or another, so they use a lot of different tools and strategies to identify bots and block them from their sites. And there are many valid points for them to do so, as badly optimized bots can slow down or even break websites.
Note: You can avoid overwhelming web servers and decrease your chances of getting blocked by following these web scraping best practices.
However, one of the ways that don’t get a lot of attention is the use of HTTP headers and cookies. Because your browser/client sends HTTP headers in its requests, the server can use this information to detect false users, thus blocking them from accessing the website or providing false/bad information.
But the same can work the other way around. By optimizing the headers sent through our bot’s requests, we can mimic the behavior of an organic user, reducing our chances of getting blacklisted and, in some cases, improving the quality of the data we collect.
Most Common HTTP Headers for Web Scraping
There are a big list of HTTP headers we could learn and use in our requests, but in most cases, there are only a few that we really care about for web scraping:
1. User-Agent
This is probably the most important header as it identifies “the application type, operating system, software vendor or software version of the requesting software user agent,” making it the first check most servers will run.
For example, when sending a request using the Requests Python library, the user-agent field will show the following information — depending on your Python version:
1 user**-**agent: python**-**requests**/**2.22.0
Which is easy to spot and block by the sever.
Instead, we want our user-agent header to look more like the one shown in our first example:
1 user**-**agent: Mozilla**/**5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit**/**537.36 (KHTML, like Gecko) Chrome**/**101.0.4951.64 Safari**/**537.36 Edg**/**101.0.1210.47
2. Accept-Language
Although it’s not always necessary, it tells the server what language version of the data to provide. When there’s a big discrepancy between each request from a language standpoint, it could tell the server there’s a bot involved.
However, technically speaking, “the server should always pay attention not to override an explicit user choice”, so if the URLs you’re scraping already have specific languages, it can still be perceived as an organic user.
Here’s how it appears in our example request:
1 accept**-**language: en**-**US,en;q**=**0.9,it;q**=**0.8,es;q**=**0.7
3. Accept-Encoding
Just as its name implies, it tells the server which compression algorithm “can be used on the resource sent back,” saving up to 70% of the bandwidth needed for certain documents, thus reducing the stress our scripts put upon servers.
1 accept**-**encoding: gzip, deflate, br
4. Referer
The Referer HTTP header tells the server the page which the user comes from. Although it’s used mostly for tracking, it can also help us to mimic the behavior of an organic user by, for example, telling the server we’ve come from a search engine like Google.
1 referer: [https:**//**prerender.io**/**](https://prerender.io/)
5. Cookie
We’ve already discussed what cookies are, however, we might haven’t stated clearly why are cookies important for web scraping.
Cookies allow servers to communicate using a small piece of data, but what happens when the server sends a cookie but then the browser doesn’t store and send it back in the next request? Cookies can be also used to identify if the request is coming from a real user or a bot.
Viceversa, we can use web cookies to mimic the organic behavior of a user when browsing a website by sending the cookies back to the server after every interaction, and by changing the cookie itself, we can tell the server we’re a new user, making it easier for our scraping scripts to avoid getting blocked.
How to View HTTP Headers? [Including Cookies]
Before we can use headers in our code, we need to be able to grab them from somewhere. To do so, let’s use our own browser and go to the target website. For our example, let’s go to google.com > right-click > inspect to open the developer tools.
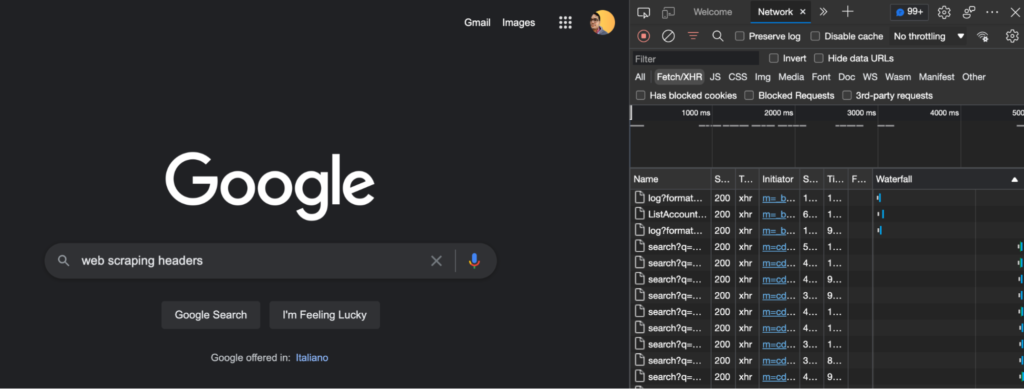
From there, we’ll navigate to the Network tab and, back on Google, search for the query “web scraping headers”.
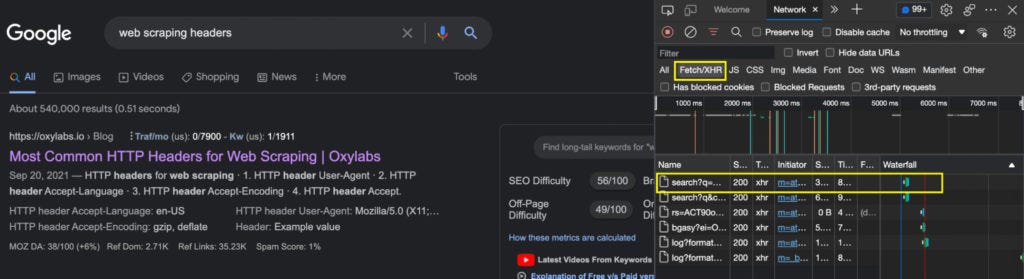
As the page loads, we’ll see the network tab populate. We’ll take a closer look at the Fetch/XHR tab, where we’ll be able to find the documents that are being fetched by the browser and, of course, the HTTP headers used in the request.
Although there’s no one single standard name for the file we’re looking for, it’s usually a relevant name for what we’re trying to do on the page or it’s the file that provides the data being rendered.
Clicking on the file we’ll open by default the Headers tab and by scrolling down we’ll see the Request Headers section.
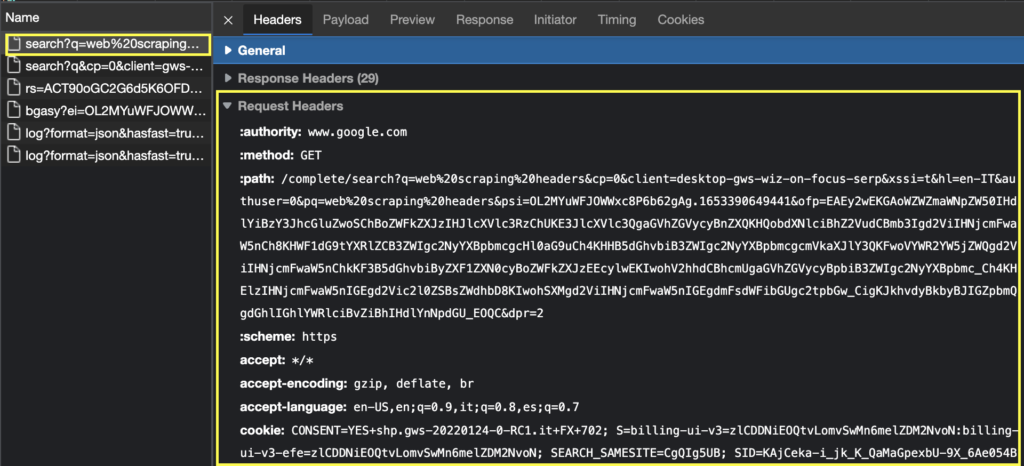
Now we can copy and paste the header fields and their value into our code.
How to Use Custom Headers for Web Scraping
The way you go about using custom headers will depend on the programming language you’re using, however, we’ll try to add as many examples as possible.
One thing you’ll notice is that: yes, each method is different but they share the same logic so no matter what codebase you’re using, it’ll be very easy to translate.
For all our examples, we’ll be sending our request to https://httpbin.org/headers which is a website designed to show how the response and requests look from the server’s points of view.
Here’s what appears if we open the link above on our browser:
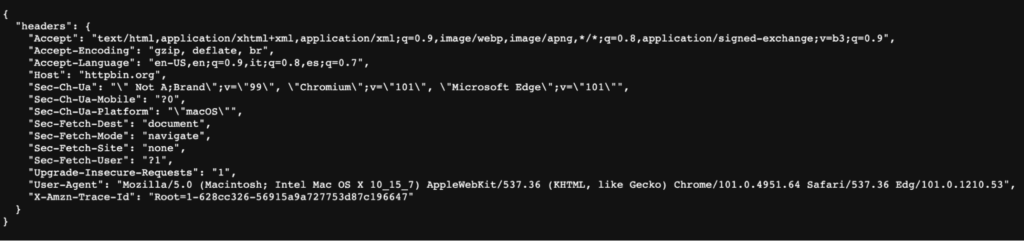
The website responds with the headers that our browser is sending, and we can now use the same headers when sending our request through code.
Using Custom Headers in Python
Before using our custom headers, let’s first send a test request to see what it returns:
**1 import** requests
2
3
4
5 url **=** '[https://httpbin.org/headers](https://httpbin.org/headers)'
6
7
8
9 response **=** requests.get(url)
10
11
12
13 print(response.text)
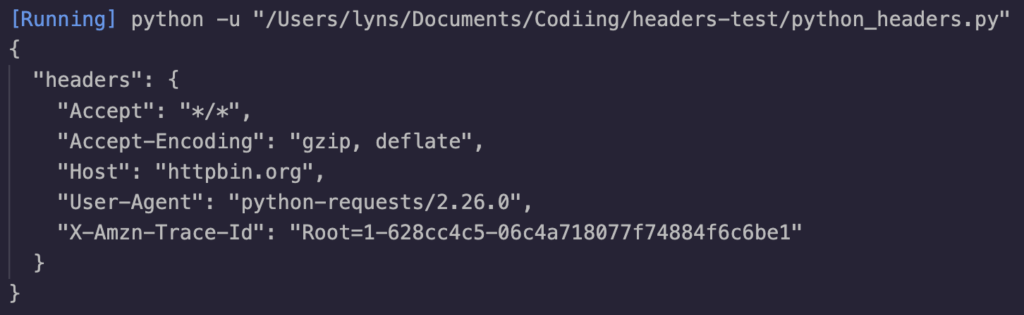
As you can see, the User-Agent being used is the default python-requests/2.26.0 which would make it super easy for a server to recognize our bot.
Knowing this, let’s move to the next step and add our custom headers to our request:
**1 import** requests
2
3 url **=** '[https://httpbin.org/headers](https://httpbin.org/headers)'
4
5 headers **=** {
6 'accept': '*/*',
7 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53',
8 'Accept-Language': 'en-US,en;q=0.9,it;q=0.8,es;q=0.7',
9 'referer': '[https://www.google.com/](https://www.google.com/)',
10 'cookie': 'DSID=AAO-7r4OSkS76zbHUkiOpnI0kk-X19BLDFF53G8gbnd21VZV2iehu-w_2v14cxvRvrkd_NjIdBWX7wUiQ66f-D8kOkTKD1BhLVlqrFAaqDP3LodRK2I0NfrObmhV9HsedGE7-mQeJpwJifSxdchqf524IMh9piBflGqP0Lg0_xjGmLKEQ0F4Na6THgC06VhtUG5infEdqMQ9otlJENe3PmOQTC_UeTH5DnENYwWC8KXs-M4fWmDADmG414V0_X0TfjrYu01nDH2Dcf3TIOFbRDb993g8nOCswLMi92LwjoqhYnFdf1jzgK0'
11 }
12
13 response **=** requests.get(url, headers**=**headers)
14
15 print(response.text)
First, we create a dictionary with our headers. Some of them we got from the HTTPbin but the cookies are from MDN documentation and we added Google as the referer because, in most cases, users will come to the site from click a link from Google.
Here’s the result:
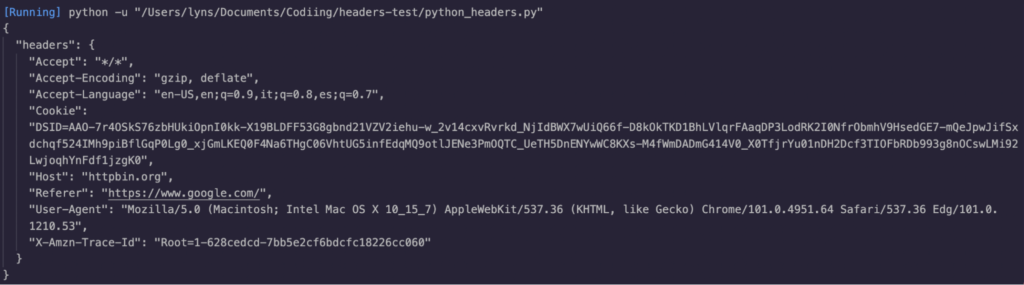
In theory, you could use custom any combination you’d like as values to your custom headers. However, some websites won’t allow you access to them without sending a specific set of headers. Whenever you’re trying to use custom headers while scraping, it’s better to see what headers your browser is already sending when navigating the target website.
Using Custom Headers in Node.JS
We’re going to do the same thing but using the Node.JS Axios package to send our request:
1 const axios **=** require('axios').default;
2
3 const url **=** '[https://httpbin.org/headers](https://httpbin.org/headers)';
4
5 const headers **=** {
6 'accept': '*/*',
7 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53',
8 'Accept-Language': 'en-US,en;q=0.9,it;q=0.8,es;q=0.7',
9 'referer': '[https://www.google.com/](https://www.google.com/)',
10 'cookie': 'DSID=AAO-7r4OSkS76zbHUkiOpnI0kk-X19BLDFF53G8gbnd21VZV2iehu-w_2v14cxvRvrkd_NjIdBWX7wUiQ66f-D8kOkTKD1BhLVlqrFAaqDP3LodRK2I0NfrObmhV9HsedGE7-mQeJpwJifSxdchqf524IMh9piBflGqP0Lg0_xjGmLKEQ0F4Na6THgC06VhtUG5infEdqMQ9otlJENe3PmOQTC_UeTH5DnENYwWC8KXs-M4fWmDADmG414V0_X0TfjrYu01nDH2Dcf3TIOFbRDb993g8nOCswLMi92LwjoqhYnFdf1jzgK0',
11 };
12
13 axios.get(url, Headers**=**{headers})
14 .then((response) **=**> {
15 console.log(response.data);
16 }, (error) **=**> {
17 console.log(error);
18 });
Here’s the result:
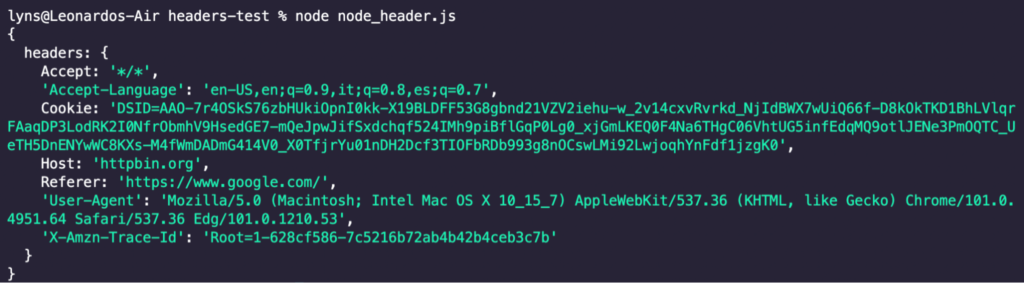
Using Custom Headers in ScraperAPI
A great feature from ScraperAPI is that it uses machine learning and years of statistical analysis to determine the best combination of headers to use for each request we send.
However, lately, we’re seeing more and more small websites improving their security measures and there is not enough data for the API to determine the optimal combination automatically. So, If you’re noticing a high failure rate, it’s worth trying to use custom headers as we’ve shown above.
In our documentation, you’ll be able to find the full list of coding examples for Node.JS, PHP, Ruby, and Java, but for the sake of time, here’s a full Python example for using ScraperAPI with custom headers:
**1 import** requests
2
3 headers **=** {
4 'accept': '*/*',
5 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53',
6 'Accept-Language': 'en-US,en;q=0.9,it;q=0.8,es;q=0.7',
7 'referer': '[https://www.google.com/](https://www.google.com/)',
8 'cookie': 'DSID=AAO-7r4OSkS76zbHUkiOpnI0kk-X19BLDFF53G8gbnd21VZV2iehu-w_2v14cxvRvrkd_NjIdBWX7wUiQ66f-D8kOkTKD1BhLVlqrFAaqDP3LodRK2I0NfrObmhV9HsedGE7-mQeJpwJifSxdchqf524IMh9piBflGqP0Lg0_xjGmLKEQ0F4Na6THgC06VhtUG5infEdqMQ9otlJENe3PmOQTC_UeTH5DnENYwWC8KXs-M4fWmDADmG414V0_X0TfjrYu01nDH2Dcf3TIOFbRDb993g8nOCswLMi92LwjoqhYnFdf1jzgK0'
9 }
10
11 payload **=** {
12 'api_key': '51e43be283e4db2a5afb62660xxxxxxx',
13 'url': '[https://httpbin.org/headers](https://httpbin.org/headers)',
14 'keep_headers': 'true',
15 }
16
17 response **=** requests.get('[http://api.scraperapi.com](http://api.scraperapi.com/)', params**=**payload, headers**=**headers)
18
19 print(response.text)
So using custom headers in Python is quite simple:
- We need to create our dictionary of headers like before and right after create our payload
- The first element we’ll add to the payload is our API Key which we can generate by creating a free ScraperAPI account
- Next, we’ll add our target URL — in this case https://httpbin.org/headers
- The last parameter will be keep_headers and set it to true to tell ScraperAPI to keep our custom headers
- Lastly, we’ll add all elements together right inside our requests.get() method
The combination of all of these we’ll result on a URL like this:
1 [http:**//**api.scraperapi.com**/**?api_key**=**51e43be283e4db2a5afb62660xxxxxxx&url**=**http:**//**httpbin.org**/**headers&keep_headers**=**true](http://api.scraperapi.com/?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=http://httpbin.org/headers&keep_headers=true)
Wrapping Up
Web scraping is both an art and science. Because every website is different, there’s no one only way to do things, so having as many tools at our disposal is crucial for our projects to be successful.
Accessing the content of a page in the right format is a crucial part of the process and using the correct HTTP headers in your requests can make the whole difference.
When using ScraperAPI you can feel safe that in 99% of cases, our API will choose and send the right headers for you, freeing your mind from the task. However, on those rare occasions when failure rates are high, try to extract and use the headers your browser sends to the target page. In our experience, that would be the trick.
Still, if you’re having trouble guaranteeing successful requests, don’t hesitate to contact us.
Until next time, happy scraping!