Hello Everyone, I am learning data science from data science central. I am a beginner in this field and i want to know the comparison between overfitting and underfitting in Predictive Performance. I am preparing my self for the next level in interview also. So if anyone knows about overfitting and underfitting, Please explain me with examples.
Overfitting
When we run our training algorithm on the data set, we allow the overall cost (i.e. distance from each point to the line) to become smaller with more iterations. Leaving this training algorithm run for long leads to minimal overall cost. However, this means that the line will be fit into all the points (including noise), catching secondary patterns that may not be needed for the generalizability of the model.
Underfitting
We want the model to learn from the training data, but we don’t want it to learn too much (i.e. too many patterns). One solution could be to stop the training earlier. However, this could lead the model to not learn enough patterns from the training data, and possibly not even capture the dominant trend. This case is called underfitting.
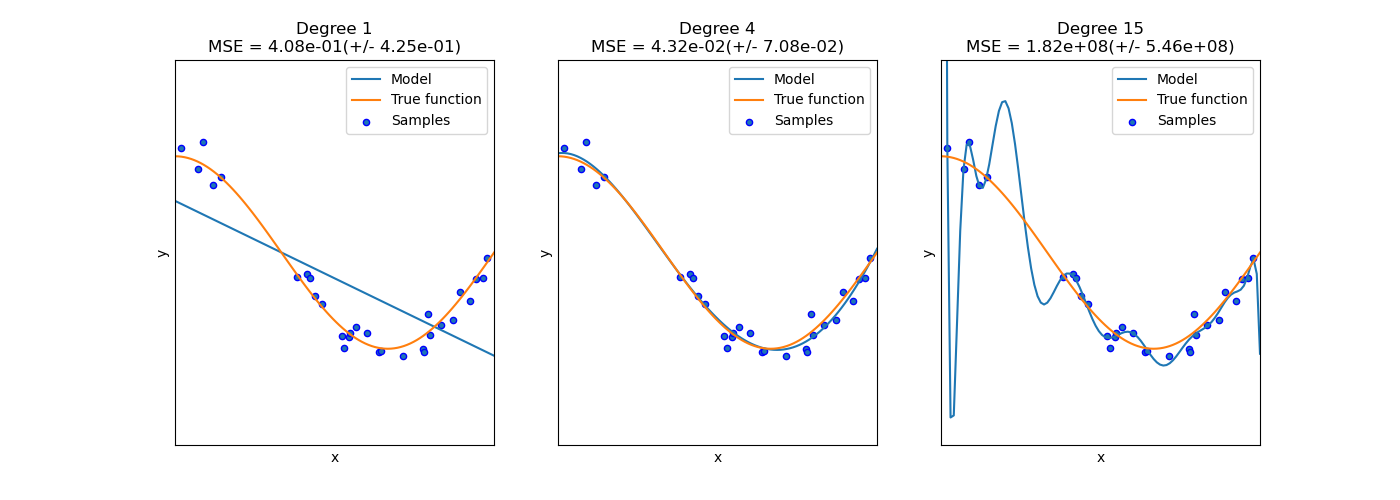
Always, always remember that data science is statistics. Model fitting is like curve fitting.
My go to mental model is trying to put a polynomial trend line through a scatter plot. If you use too high of a degree polynomial, you exactly fit every point in the plot but you don’t see a trend. If you use too low of a degree polynomial, your trend line misses the general trend of the data.
Here is a good graphic [https://scikit-learn.org/stable/_images/sphx_glr_plot_underfitting_overfitting_001.png]
{kind=link}
Thanks @khatrivijaysingh1994 and @JeremyLT to clear my doubt in the comparison between overfitting and underfitting. Although both overfitting and underfitting yield poor predictive performance, the way in which each one of them does so is different. While the overfitted model overreacts to minor fluctuations in the training data, the underfit model under-reacts to even bigger fluctuations.